Chapter 03. 회귀 알고리즘과 모델 규제
03-1 k-최근접 이웃 회귀
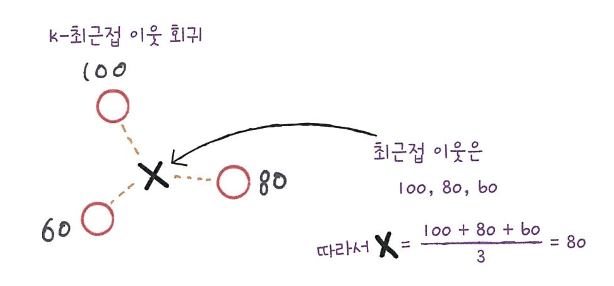
✅ k-최근접 이웃 회귀
지도 학습 알고리즘은 크게 분류와 회귀로 나뉩니다. 회귀는 클래스 중 하나로 분류하는 것이 아니라 임의의 어떤 숫자를 예측하는 문제입니다. 회귀는 정해진 클래스가 없고 임의의 수치를 출력합니다.
k-최근접 이웃 회귀도 kNN 알고리즘과 같이 간단합니다.
- 예측하려는 샘플에 가장 가까운 샘플 k개를 선택합니다. 하지만 이웃한 샘플의 타깃은 어떤 클래스가 아니라 임의의 수치입니다.
- 이웃한 수치들의 평균을 구해 예측 타깃값을 구합니다.
✅ 데이터 준비
reshape() 메서드
사이킷런에 사용할 훈련 세트는 2차원 배열이어야 합니다. 넘파이 배열에서는 배열의 크기를 바꿀 수 있는 reshape() 메서드를 제공합니다.
test_array = np.array([1,2,3,4])
print(test_array.shape)
#->(4, )test_array = test_array.reshape(2,2)
print(test_array.shape)
#-> (2, 2)
이처럼 reshape() 메서드는 바꾸려는 배열의 크기를 지정할 수 있지만 지정한 크기와 원본 배열의 원소 개수가 다르면 에러가 발생합니다.
넘파이는 배열의 크기를 자동으로 지정하는 기능도 제공하는데요. 크기에 -1을 지정하면 나머지 원소 개수로 모두 채우라는 의미입니다.
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
print(train_input.shape, test_input.shape)
#-> (42, 1) (14, 1)✅ 결정계수(R²)
사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스는 KNeighborsRegressor입니다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)이 테스트 세트의 점수를 확인해 보죠.
print(knr.score(test_input, test_target))
#-> 0.992809406101064그런데 이 점수는 무엇일까요? 회귀에서는 정확한 숫자를 맞힌다는 것은 거의 불가능합니다. 회귀의 경우에는 이 점수를 결정계수라고 부릅니다. 또는 간단히 R²라고도 부릅니다. 이 값은 다음과 같은 식으로 계산됩니다.
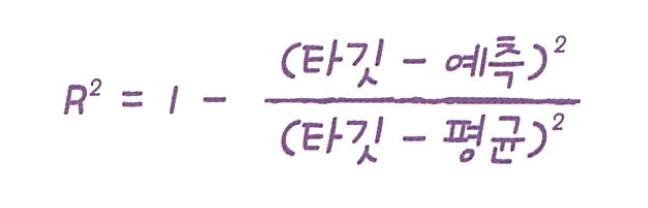
❓먼저 타깃과 예측한 값의 차이를 제곱합니다. 그다음 타깃과 타깃 평균의 차이를 제곱한 값으로 나눕니다. 만약 타깃의 평균 정도를 예측하는 수준이라면 R²는 0에 가까워지고, 타깃이 예측에 아주 가까워지면 1에 가까운 값이 됩니다.❓
✅ 과대적합 vs 과소적합
지금까지는 훈련 세트를 사용해 모델을 훈련하고 테스트 세트로 모델을 평가했습니다. 그런데 훈련 세트를 사용해 평가해 보면 어떨까요? 앞에서 훈련한 모델을 사용해 훈련 세트의 R² 점수를 확인하겠습니다.
print(knr.score(train_input, train_target))
#-> 0.9698823289099254모델을 훈련 세트와 테스트 세트에서 평가하면 보통 훈련 세트의 점수가 조금 더 높게 나옵니다. 만약 훈련 세트에서 점수가 굉장히 좋았는데 테스트 세트에서는 점수가 굉장히 나쁘다면 모델이 훈련 세트에 과대적합되었다고 말합니다. 반대로 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 낮은 경우에는 모델이 훈련 세트에 과소적합되었다고 말합니다. 훈련 세트가 전체 데이터를 대표한다고 가정하기 때문에 훈련 세트를 잘 학습하는 것이 중요합니다.
* 과소적합이 일어나는 이유 -> 훈련 세트와 테스트 세트의 크기가 매우 작기 때문에
과소적합 해결 방법 : 모델을 조금 더 복잡하게 만들기 -> 이웃의 개수 k를 줄이는 방법
이웃의 개수를 줄이면 훈련 세트에 있는 국지적인 패턴에 민감해지고, 이웃의 개수를 늘리면 데이터 전반에 있는 일반적인 패턴을 따를 것임.
knr.n_neighbors = 3
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
#-> 0.9804899950518966
print(knr.score(test_input, test_target))
#-> 0.9746459963987609
반대로 과대적합 해결 방법 : 모델을 덜 복잡하게 만들기 -> 이웃의 개수 k를 늘리는 방법
03-2 선형 회귀
✅ k-최근접 이웃의 한계
k-최근접 이웃에서는 근처에 있는 샘플들의 타깃값을 평균하여 예측하기 때문에 거리가 얼마나 멀든 결과값이 똑같이 나올 수 있다.
✅ 선형 회귀
선형 회귀는 특성이 하나인 경우 특성을 가장 잘 나타낼 수 있는 직선을 학습하는 알고리즘입니다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]]))
#-> [1241.83860323]
하나의 직선을 그리려면 기울기와 절편이 있어야 합니다. y = a * x + b처럼 쓸 수 있죠. 여기에서 x를 농어의 길이, y를 농어의 무게로 바꾸면 다음과 같습니다.

LinearRegression 클래스가 찾은 a(기울기)와 b(y절편)는 lr 객체의 coef_와 intercept_ 속성에 저장되어 있습니다.
print(lr.coef_, lr.intercept_)
#-> [39.01714496] -709.0186449535477
* coef_속성 이름에서 알 수 있듯이 머신러닝에서 기울기를 종종 계수(coefficient) 또는 가중치(weight)라고 부릅니다.
coef_와 intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 부릅니다. 훈련 과정에서 최적의 모델 파라미터를 찾는 머신러닝 알고리즘은 모델 기반 학습이라고 부릅니다. 앞서 사용한 k-최근접 이웃처럼 모델 파라미터 없이 훈련 세트를 저장하는 것이 훈련의 전부인 학습을 사례 기반 학습이라고 부릅니다.
✅ 다항 회귀
직선으로는 샘플을 정확하게 표현하기 어려움 -> 최적의 곡선 찾기

이런 그래프를 그리려면 길이를 제곱한 항이 훈련 세트에 추가되어야 합니다.
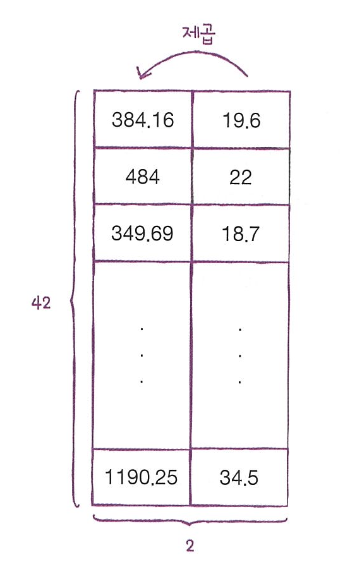
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
print(train_poly.shape, test_poly.shape)
#-> (42, 2) (14, 2)
길이를 제곱하여 왼쪽 열에 추가했기 때문에 훈련 세트와 테스트 세트 모두 열이 2개로 늘어났습니다.
여기서 주목할 점은 2차 방정식 그래프를 찾기 위해 훈련 세트에 제곱 항을 추가했지만, 타깃값은 그대로 사용한다는 것입니다.
이제 train_poly를 사용해 선형 회귀 모델을 훈련할 때는 이 모델에 농어 길이의 제곱과 원래 길이를 함께 넣어 주어야 합니다.
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
#-> [1573.98423528]
print(lr.coef_, lr.intercept_)
#-> [ 1.01433211 -21.55792498] 116.0502107827827
이 모델은 다음과 같은 그래프를 학습했습니다. <무게 = 1.01 * 길이² - 21.6 * 길이 + 116.05>
이 식은 2차 방정식인데 그럼 비선형 아닌가요? 선형이라고 부르는 것은 1차여서가 아니라 식이 선형적으로 표현되기 때문입니다.
이런 방정식을 다항식이라 부르며 다항식을 사용한 선형 회귀를 다항 회귀라고 부릅니다.
point = np.arange(15, 50)
plt.scatter(train_input, train_target)
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
plt.scatter([50], [1574], marker='^')
plt.show()
훈련 세트와 테스트 세트의 R² 점수를 평가하겠습니다.
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
#-> 0.9706807451768623
#-> 0.9775935108325122
훈련 세트와 테스트 세트에 대한 점수가 크레 높아졌습니다. 하지만 과소적합이 남아 있어서 더 복잡한 모델이 필요합니다.
✅ 선형 회귀로 훈련 세트 범위 밖의 샘플 예측
k-최근접 이웃 회귀 -> 선형 회귀 -> 다항 회귀
➡️ k-최근접 이웃 회귀의 문제점 : 무조건 가장 가까운 샘플의 타깃을 평균하여 예측하기 때문에 훈련 세트 밖의 샘플을 예측할 수 없다.
➡️ 선형 회귀의 문제점 : 모델이 단순해서 있을 수 없는 값(ex 무게가 음수)이 나올 수 있다.
➡️ 다항 회귀 -> k-최근접 이웃 회귀와 선형 회귀의 문제점을 다 해결했지만 과소적합된 경향이 남아있다. -> 해결 방안 : 더 복잡한 모델
✅ 사이킷런의 변환기
사이킷런은 특성을 만들거나 전처리하기 위한 변환기라는 클래스를 제공합니다. 변환기 클래스는 모두 fit(), transform() 메서드를 제공합니다.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
#-> [[1. 2. 3. 4. 6. 9.]]
fit() 메서드는 새롭게 만들 특성 조합을 찾고 transform() 메서드는 실제로 데이터를 변환합니다.
PolynomialFeatures 클래스는 기본적으로 각 특성을 제곱한 항을 추가하고 특성끼리 서로 곱한 항을 추가합니다.
1은 절편이 자동으로 설정되는 절편값입니다.
훈련(fit)을 해야 변환(transform)이 가능합니다. 두 메서드를 하나로 붙인 fit_transform 메서드도 있습니다.
poly = PolynomialFeatures(include_bias=False)
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
#-> [[2. 3. 4. 6. 9.]]절편이 제거되고 특성의 제곱과 특성끼리 곱한 항만 추가되었습니다.
include_bias=False로 지정하지 않아도 사이킷런 모델은 자동으로 특성에 추가된 절편 항을 무시합니다. 하지만 명시적으로 제거하는 게 좋습니다.
poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
print(train_poly.shape)
#-> (42, 9)
get_feature_names_out() 메서드를 호출하면 9개의 특성이 각각 어떤 입력의 조합으로 만들어졌는지 알려 줍니다.
PolynomialFeatures 클래스에서는 꼭 훈련 세트에 적용했던 변환기로 테스트 세트를 변환할 필요가 없습니다. 하지만 항상 훈련 세트를 기준으로 테스트 세트를 변환하는 습관을 들이는 것이 좋습니다.
✅ 다중 회귀 모델 훈련하기
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
#-> 0.9903183436982125
print(lr.score(test_poly, test_target))
#-> 0.9714559911594111
그리고 PolynomialFeatures 클래스의 degree 매개변수를 사용하여 5제곱까지 특성을 만들어 출력해 보겠습니다.
poly = PolynomialFeatures(degree=5, include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)
print(train_poly.shape)
#-> (42, 55)
만들어진 특성의 개수가 무려 55개나 됩니다. 이 데이터를 사용해 선형 회귀 모델을 다시 훈련하겠습니다.
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
#-> 0.9999999999996433
print(lr.score(test_poly, test_target))
#-> -144.40579436844948
특성의 개수를 크게 늘리면 선형 모델은 아주 강력해집니다. 하지만 이런 모델은 훈련 세트에 너무 과대적합되므로 테스트 세트에는 형편없는 점수를 만듭니다.
42개의 샘플을 55개의 특성으로 훈련하면 완벽하게 학습할 수 있는 것이 당연합니다.
✅ 규제
규제는 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말합니다. 선형 회귀 모델의 경우 특성에 곱해지는 계수(또는 기울기)의 크기를 작게 만드는 일입니다.

2장에서 보았듯이 특성의 스케일이 정규화되지 않으면 여기에 곱해지는 계수 값도 차이 나게 됩니다. 따라서 규제를 적용하기 전에 먼저 정규화를 해야합니다. 이번에는 표준점수로 바꾸는 게 아닌, 사이킷에서 제공하는 변환기 중 하나인 StandardScaler 클래스를 사용하겠습니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)꼭 훈련 세트로 학습한 변환기를 사용해 테스트 세트까지 변환해야 합니다.
선형 회귀 모델에 규제를 추가한 모델을 릿지와 라쏘라고 부릅니다. 릿지는 계수를 제곱한 값을 기준으로 규제를 적용하고, 라쏘는 계수의 절댓값을 기준으로 규제를 적용합니다.
✅ 릿지 회귀
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
#-> 0.9896101671037343
print(ridge.score(test_scaled, test_target))
#-> 0.9790693977615387
릿지와 라쏘 모델을 사용할 때 규제의 양을 임의로 조절할 수 있습니다. 모델 객체를 만들 때 alpha 매개변수로 규제의 강도를 조절합니다. alpha 값이 크면 -> 규제 강도가 세짐 -> 계수 값을 더 줄이고 조금 더 과소적합되도록 유도
alpha 값이 작으면 -> 규제 강도가 약해짐 -> 선형 회귀 모델과 유사해지므로 과대적합될 가능성이 큼
alpha 값처럼 머신러닝 모델이 학습할 수 없고 사람이 알려줘야 하는 파라미터를 하이퍼파라미터라고 부릅니다.
적절한 alpha 값을 찾는 한 가지 방법은 alpha 값에 대한 R²값의 그래프를 그려 보는 것입니다. 훈련 세트와 테스트 세트의 점수가 가장 가까운 지점이 최적의 alpha 값이 됩니다.
import matplotlib.pyplot as plt
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
ridge = Ridge(alpha=alpha)
ridge.fit(train_scaled, train_target)
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.show()
alpha 값이 0.1일 때 두 그래프가 가장 가깝고 테스트 세트의 점수가 가장 높습니다. alpha 값을 0.1로 하여 최종 모델을 훈련하겠습니다.
ridge = Ridge(alpha=0.1)
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
#-> 0.9903815817570367
#-> 0.9827976465386928✅ 라쏘 회귀
라쏘 모델을 훈련하는 것은 릿지와 매우 비슷합니다.
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
#-> 0.989789897208096
print(lasso.score(test_scaled, test_target))
#-> 0.9800593698421883train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
lasso = Lasso(alpha=alpha, max_iter=10000)
lasso.fit(train_scaled, train_target)
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))라쏘 모델을 훈련할 때 ConvergenceWarning이란 경고가 발생할 수 있습니다. 사이킷런의 라쏘 모델은 최적의 계수를 찾기 위해 반복적인 계산을 수행하는데, 지정한 반복 횟수가 부족할 때 이런 경고가 발생합니다. 이 반복 횟수를 충분히 늘리기 위해 max_iter 매개변수의 값을 10000으로 지정했습니다.
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.show()
lasso = Lasso(alpha=10)
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
#-> 0.9888067471131867
#-> 0.9824470598706695
라쏘 모델의 계수는 coef_속성에 저장되어 있습니다. 이 중에 0인 것을 헤아려 보겠습니다.
print(np.sum(lasso.coef_ == 0))
#-> 40